SAP HANA – backup size increased
In last time I had problem with my HANA backup. The size of backup everyday increased although in the database not appeard new data. Generally normal backup size oscillates around 1.4TB but in last day I saw:
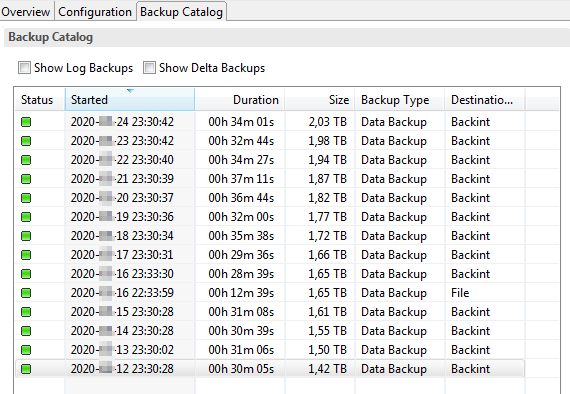
The change in backup sizes can be due to many reasons. Delta store has changed data but that data is only compressed when delta merge happens. So, if there’s was a huge load and data was backed up after that before the delta merge on the table happened then that backup size will definitely be larger than the backup size that is taken after delta merge happens on it.
Also, the size of savepoint affects the size of backup.
To verify you can use some of the below scripts such as-
HANA_Disks_Overview.txt
HANA_Tables_DiskSize_1.00.120+.txt
HANA_Configuration_MiniChecks_1.00.121+.txt
HANA_Tables_TopGrowingTables_Size_History_1.00.70+.txt HANA_IO_Savepoints.txt
The above scripts can be found from SAP NOTE 1969700
Also, my system has system replication set-up, there might be possibility that hana backup sizes increases based on old snapshots exists for a long time on data volume and when the hana backup gets trigger, backup will take all data volume backup including snapshots.
You can refer Note 2562939 – HANA Data Volume Used Size is Doubled or Much Larger than Before
According to above note I try reclaim DATA space, but I receive error:
ALTER SYSTEM RECLAIM DATAVOLUME 120 DEFRAGMENT; Could not execute 'ALTER SYSTEM RECLAIM DATAVOLUME 120 DEFRAGMENT' in 78 ms 161 µs . SAP DBTech JDBC: [2]: general error: Shrink canceled, probably because of snapshot pages
For this, Please check sap note 1999880 – FAQ: SAP HANA System Replication -> section 19. How can RECLAIM DATAVOLUME be executed when system replication is active? I found also another note: 2332284 – Data volume reclaim failed because of snapshot pages. I checked all and see that I can reclaim ~880GB (my unused space):

In the last note (2332284) You can find very importnant information, e.g.:
1) The replication process creates snapshots from time to time. These snapshots will be deleted automatically later, so checking for active snapshots might not return any results. But while they exist, they conflict with the datavolume reclaim run. Therefore it is necessary to pause snapshot creation for the duration of the reclaim.
2) As database backups also create a ‘backup snapshot’ within a data volume, the ‘alter system reclaim datavolume ‘<hostname>:<port>’ 120 defragment’ statement might also fail after a certain amount of time if it then finds pages belonging to a ‘backup snapshot’. Please make sure that there is no data backups currently running and there will be no scheduled data backups until you finish the reclaim. The data backup process will also create snapshots and lead to reclaim failure.
3) If you are using replication mode ‘logreplay’ or ‘logreplay_readaccess’ and want to keep replication on during the reclaim and follow from point 1 till point 5.
-- SAP HANA reclaim unused data 1. Set the following parameters to large values on primary site, so they are not hit while replication is going on and no new snapshots are getting created. datashipping_logsize_threshold: 5368709120 -> 20737418240 datashipping_min_time_interval: 600 -> 10800 2. On primary site, drop existing replication snapshots e.g. by using hdbnsutil -sr_dropsnapshots 3. Disable log retention on secondary site by setting global.ini [system_replication] enable_log_retention = false enable_log_retention: auto -> my default value server:sidadm> pwd /usr/sap/SID/SYS/global/hdb/custom/config -- use new parameters without instance restart hdbnsutil –reconfig 4. Execute data volume reclaim on primary site ALTER SYSTEM RECLAIM DATAVOLUME 120 DEFRAGMENT; SELECT * FROM M_SNAPSHOTS; -> check snapshot 5. After you finish data volume reclaim, revert all changed parameters to their original values
If above reclaim unused data don’t be work correctly I will suggest You another way:
1. Run HANA_Disks_Data_Overview* and HANA_Disks_Data_SuperBlockStatistics* from SAP Note 1969700. 2. Disable replication. Run following to be sure there is nothing related to the replication : hdbnsutil –sr_disable 3. Run following to drop possible snaphots hdbnsutil -sr_dropsnapshots 4. Run savepoint alter system savepoint 5. Then, run reclaim operation 6. Check again by Running HANA_Disks_Data_Overview* and HANA_Disks_Data_SuperBlockStatistics* from SAP Note 1969700 7. reconfigure the replication .
As replication will be disabled , so there is no need to change any other parameters. You can revert all changed parameters to their original values.
At the end one more very importnt information for You from note: 2400005 – FAQ: SAP HANA Persistence. Please look to point 7. How can the persistence be defragmented?
The RECLAIM task is resumable, so if it is terminated (e.g. due to “general error: Shrink canceled, probably because of snapshot pages”, SAP Note 1999880), it will continue next time at roughly the place where it stopped.
When RECLAIM is run in parallel to production load and modifications there is a certain risk of significant runtime overhead depending on the used SAP HANA Revision level:
SAP HANA 1.0: Rather high risk of runtime overhead
SAP HANA 2.0 <= SPS 03: Reduced risk of runtime overhead
SAP HANA 2.0 >= SPS 04: Further optimizations to reduce risk of runtime overhead